Google launches Gemma 4 12B, bringing frontier AI model to everyday laptops

Google has spent the past year pushing AI models into phones, laptops, and edge devices. The challenge has always been the same: powerful multimodal models typically demand large amounts of memory and specialized hardware.
Google DeepMind thinks it has found a way around that problem.
Gemma 4 12B: An Encoder-Free AI Model Built for Consumer Laptops
On Wednesday, the company released Gemma 4 12B, a new open-source multimodal model that delivers advanced reasoning, coding, vision, and audio capabilities on hardware many developers already own.
“Today, we are introducing Gemma 4 12B, our latest model designed to bring agentic multimodal intelligence directly to laptops. Bridging the gap between our edge-friendly E4B and our more advanced 26B Mixture of Experts (MoE), Gemma 4 12B packages powerful capabilities inside a reduced memory footprint. It is also our first mid-sized model to feature native audio inputs,” Google said in a blog post.
The release is available under the Apache 2.0 license, giving developers and businesses broad freedom to use, modify, and commercialize the model.
Google also highlighted the launch on X, writing:
“Meet Gemma 4 12B! A unified, encoder-free multimodal model designed to bring high-performance intelligence directly to your laptop, and released under an Apache 2.0 license. Bridging the gap between edge efficiency and advanced reasoning. Here is what’s new with Gemma 4 12B.”
Unlike many modern multimodal systems that rely on separate vision and audio encoders, Gemma 4 12B takes a different path. The model processes multiple data types through a unified architecture, reducing memory overhead and simplifying deployment.
The release is available under the Apache 2.0 license, giving developers and businesses broad freedom to use, modify, and commercialize the model.
A different approach to multimodal AI
Most multimodal AI systems are built around multiple specialized components. Images are typically processed through large vision encoders before being passed to the language model. Audio follows a similar path through dedicated speech-processing networks.
That architecture works well, but it comes with tradeoffs. Extra components consume memory, increase latency, and add engineering complexity.
Gemma 4 12B removes much of that machinery.
For images, the model uses a lightweight 35-million-parameter vision module that converts image patches into tokens, then feeds them directly into the transformer backbone. Audio processing is even more streamlined. Raw 16 kHz audio is transformed directly into the model’s token space without requiring a dedicated audio encoder.
The result is what DeepMind describes as an “encoder-free multimodal” architecture. Text, images, and audio flow through a unified decoder-only transformer rather than separate processing pipelines.
The model includes Multi-Token Prediction (MTP) drafters for speculative decoding, a technique that can significantly increase inference speed.
Gemma 4 12B benchmarks: Punching above its weight
What makes Gemma 4 12B notable is not just its architecture but also how closely it matches larger systems.
According to benchmarks released alongside the model, Gemma 4 12B delivers performance approaching the larger Gemma 4 26B mixture-of-experts model in several reasoning and multimodal tasks while requiring less than half the memory footprint.
The model achieved 78.8% on GPQA Diamond, a benchmark focused on graduate-level science questions. It scored 77.2% on MMLU Pro and 72% on LiveCodeBench v6, which evaluates real-world coding performance.
Multimodal benchmarks were equally strong. Gemma 4 12B reached 94.9% on DocVQA, 88.4% on InfoVQA, and 69.1% on MMMU Pro. On mathematical reasoning tasks, it posted 77.5% on AIME 2026 and 79.7% on MATH-Vision.
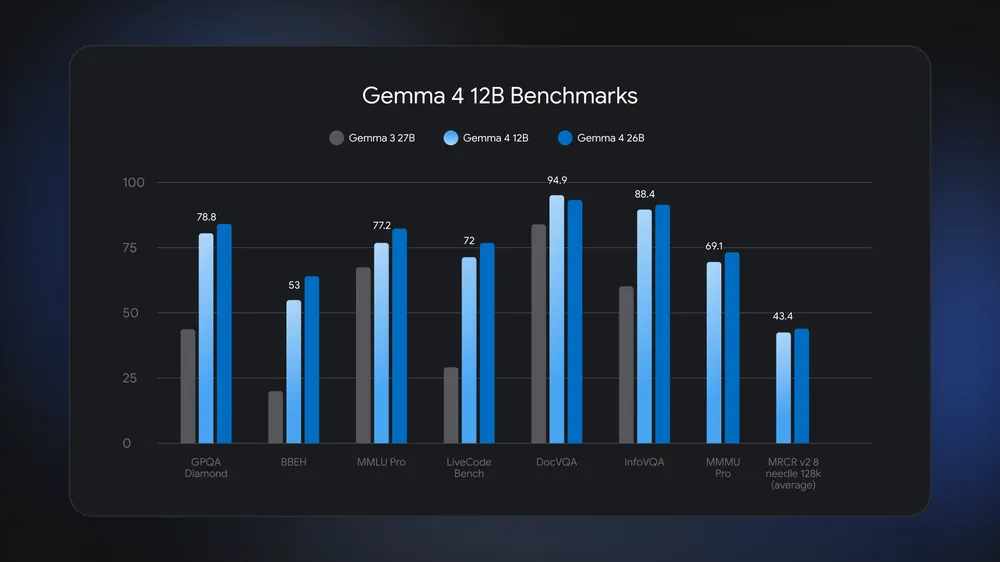
Gemma 4 12B Benchmarks
The model supports a 256,000-token context window, providing sufficient capacity to handle lengthy documents, large codebases, research materials, and agentic workflows that require extended reasoning.
Built for the laptops developers already use
A major part of DeepMind’s pitch centers on accessibility.
Large AI models often force developers to choose between cloud infrastructure and heavily quantized local deployments. Gemma 4 12B targets a middle ground.
The model is optimized for laptops and desktop systems equipped with roughly 16 GB of VRAM or unified memory. That includes many modern Windows machines and Apple’s MacBook lineup.
Early community testing has produced encouraging results. One developer reported generating approximately 21 tokens per second on an RTX 4060 using Unsloth’s dynamic GGUF quantization and llama.cpp.
The model supports text and image inputs out of the box, includes native audio capabilities, and can handle tool calling, multi-step reasoning, offline coding tasks, and local agent workflows.
Open source from day one
Google is releasing Gemma 4 12B into an ecosystem that has matured considerably over the past year.
Model weights are already available through Hugging Face and Kaggle. Support is live across popular inference frameworks including llama.cpp, MLX for Apple Silicon, vLLM, LM Studio, SGLang, and Unsloth.
Developers interested in customization can fine-tune the model through Hugging Face TRL, Unsloth, Google Colab, or Vertex AI.
Why this release matters
The AI industry has spent much of the past two years chasing larger models, larger clusters, and larger infrastructure budgets.
Gemma 4 12B points in a different direction.
The model shows that advanced multimodal capabilities no longer need to live exclusively inside data centers packed with expensive GPUs. DeepMind’s encoder-free approach reduces overhead, lowers hardware requirements, and makes local deployment practical for a much broader audience.
That shift could have implications far beyond hobby projects. Privacy-focused assistants, offline coding tools, local retrieval systems, enterprise knowledge agents, and creative applications all become more feasible when capable models can run directly on consumer hardware.
The bigger story is not the model’s size but where it can run.
For years, advanced multimodal AI has largely been associated with powerful cloud infrastructure and expensive GPUs. Gemma 4 12B suggests the gap is narrowing. By combining strong reasoning, coding, vision, and audio capabilities in a model that fits comfortably on many modern laptops, Google is betting that the next wave of AI development will happen closer to the user rather than exclusively in the data center.
Gemma 4 12B is not Google’s largest model. It may end up being one of its most practical.
Trending Now



