
On Wednesday, Google surprised everyone by launching Gemini, its largest and most powerful AI model to date. However, there’s a twist in the story as The Information’s report hinted at a potential delay in the full launch until 2024. It seems Google decided to postpone the release due to some readiness issues, bringing back memories of the company’s earlier shaky release of AI tools this year.
Gemini, boasting the capability to outperform OpenAI’s GPT-4, faced immediate scrutiny from various tech media outlets. TechCrunch, in particular, published an article claiming that “Google’s best Gemini demo was faked.” The focal point of their argument is a video titled “Hands-on with Gemini: Interacting with multimodal AI,” which has gained almost two million views in the last three days.
According to TechCrunch, the demo video was deemed fake because it wasn’t conducted in real time or with actual voice interaction. They backed up its claim with a tweet from Parmy Olson, who first highlighted the discrepancy based on a statement from Google’s spokesperson who told Olson that the demonstration didn’t occur in real-time or with spoken voice, according to a statement from a Google spokesperson. Instead, it was created by “using still image frames from the footage, and prompting via text.”
“PSA about Google’s jaw-dropping video demo of Gemini – the one with the duck:
“It was not carried out in real time or in voice. The model was shown still images from video footage and human prompts narrated afterwards, per a spokesperson More here: bloomberg.com/opinion/articl” Olson wrote.
https://twitter.com/parmy/status/1732811357068615969
Did Google Really Fake its Hands-on Gemini AI Video?
So, did Google actually fake its hands-on demo video for Gemini AI? To get to the bottom of this, it’s crucial to note that TechCrunch’s article was based on Olson’s post on X, which included a link to a now-deleted Bloomberg article.
Adding another layer to the story, it was a Google spokesperson who informed Olson that the Gemini demo wasn’t conducted in real-time or with actual voice interaction. Instead, the model was shown still images from video footage, with human prompts narrated afterward.
In essence, contrary to what the article implies, the impressive hands-on Gemini AI video that Google shared during the platform’s launch wasn’t entirely real. It wasn’t a complete fabrication either, but rather a representation of “what Gemini could look like,” offering a glimpse into the potential rather than a real-time demonstration as many viewers believed.
However, some may argue that at 2:45 in the video, TechCrunch highlighted a moment where “a hand silently makes a series of gestures. Gemini swiftly responds, ‘I know what you’re doing! You’re playing Rock, Paper, Scissors!'”

Image Credits: Google/YouTube
As the article correctly stated, the initial information in the capability documentation clearly states that the model doesn’t make deductions based on individual gestures. It requires all three gestures to be presented simultaneously, along with a prompt.
“But the very first thing in the documentation of the capability is how the model does not reason based on seeing individual gestures. It must be shown all three gestures at once and prompted: “What do you think I’m doing? Hint: it’s a game.” It responds, “You’re playing rock, paper, scissors.””
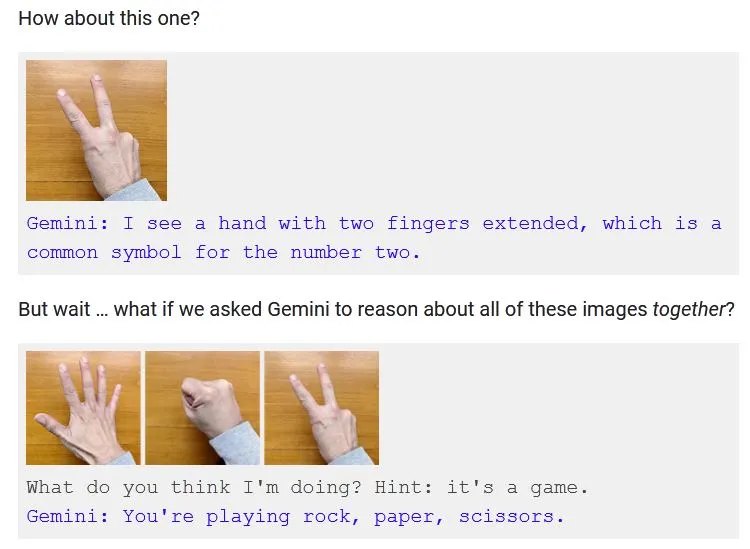
The article also pointed out that despite the seeming similarity, these interactions didn’t come across as the same because of Gemini’s limitations in performing all the tasks demonstrated in the hands-on video. As such, TechCrunch concluded the “interaction” shown in the video did not take place.
“Despite the similarity, these don’t feel like the same interaction. They feel like fundamentally different interactions, one an intuitive, wordless evaluation that captures an abstract idea on the fly, another an engineered and heavily hinted interaction that demonstrates limitations as much as capabilities. Gemini did the latter, not the former. The “interaction” showed in the video didn’t happen.”
However, the counterargument to this claim is that, as Olson also noted in her piece on Bloomberg, the YouTube description of the video has the following disclaimer:
“For the purposes of this demo, latency has been reduced and Gemini outputs have been shortened for brevity.”
This suggests that the AI model might have needed more time to respond according to a Google spokesperson who acknowledged that the demo was created by “using still image frames from the footage, and prompting via text.”
Interestingly, the way Gemini operates is more AI-centric than the demo portrayed. Google’s Vice President of Research and the co-lead for Gemini went on to showcase the actual workings of Gemini.
Really happy to see the interest around our “Hands-on with Gemini” video. In our developer blog yesterday, we broke down how Gemini was used to create it. https://t.co/50gjMkaVc0
We gave Gemini sequences of different modalities — image and text in this case — and had it respond… pic.twitter.com/Beba5M5dHP
— Oriol Vinyals (@OriolVinyalsML) December 7, 2023
Did Google Lie About the Demo Video?
No, Google was clear and upfront that the demo “wasn’t conducted in real-time or using spoken voice.” In a response to Bloomberg Opinion, a Google spokesperson said that the video was created “using still image frames from the footage, and prompting via text.”
“In reality, the demo also wasn’t carried out in real time or in voice. When asked about the video by Bloomberg Opinion, a Google spokesperson said it was made by “using still image frames from the footage, and prompting via text,” and they pointed to a site showing how others could interact with Gemini with photos of their hands, or of drawings or other objects. In other words, the voice in the demo was reading out human-made prompts they’d made to Gemini, and showing them still images. That’s quite different from what Google seemed to be suggesting: that a person could have a smooth voice conversation with Gemini as it watched and responded in real time to the world around it,” Olso wrote on Bloomberg.
Trending Now



