Apple unveils its MM1 multimodal large language models as generative AI race heats up

Apple’s foray into artificial intelligence just took a significant leap forward with the quiet unveiling of MM1, a groundbreaking series of multimodal large language models (LLMs). In a recent paper, Apple’s research team introduced MM1, showcasing its prowess in merging visual and language understanding, thus paving the way for cutting-edge capabilities.
The debut of the MM1 models comes just a few days following reports that Apple quietly acquired Canadian AI startup DarwinAI to deepen its AI push. The move, kept under wraps until now, underscores Apple’s commitment to advancing AI technologies, particularly as it prepares to release iOS 18 later this year.
What is MM1?
The MM1 model, known as “Multi-Modal 1,” shares similarities with other language models like GPT-4V and Gemini. Built upon the Large Language Model (LLM) architecture, MM1 underwent training using a diverse dataset comprising image-text pairs, interleaved image-text documents, and text-only data (with a distribution of 45% image-text pairs, 45% interleaved image-text documents, and 10% text-only data).
What sets MM1 apart is its unique ability to process both image recognition and natural language processing simultaneously, rendering it a versatile powerhouse capable of mastering a wide array of tasks with finesse. This versatility empowers it to handle a myriad of tasks such as generating image captions, answering image-based queries, and discerning connections between disparate pictures.

While Apple has remained tight-lipped about any forthcoming products, the implications of this research suggest that MM1 could seamlessly integrate into future devices. This could potentially revolutionize functionalities within Siri or enhance photo features on iPhones and iPads.
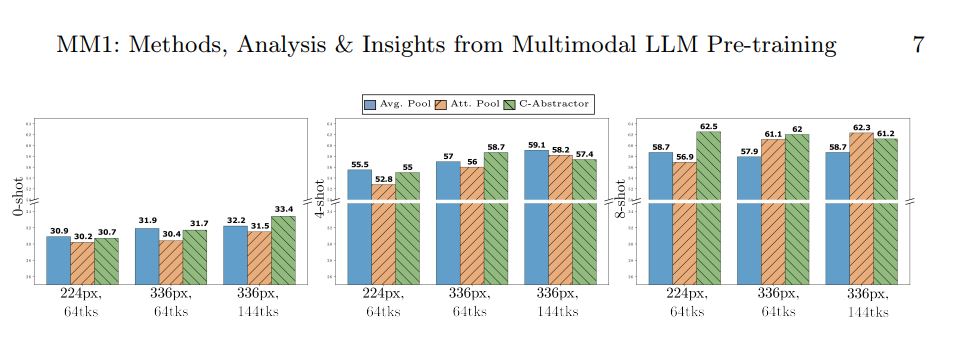
The MM1 models underwent meticulous training on a curated blend of image captions, image-text amalgamations, and text-only datasets.
Of particular note is the performance of the largest 30B parameter model, which exhibited remarkable adeptness in learning from minimal examples and deducing insights across multiple images.
Notably, the research underscored the pivotal role of scaling the model’s image-processing capabilities in enhancing its overall performance.
In terms of benchmarks, MM1 stands shoulder to shoulder with state-of-the-art multimodal models like GPT-4V and Gemini Pro. Apple’s departure from its customary veil of secrecy surrounding this model release marks a significant shift, heralding a triumph for the open-source community. With a robust model now officially unveiled, the question beckons: Is it finally time for Siri to step up its game?
Trending Now



