OpenAI launches GPT-4 with better accuracy, claims it can beat 90% of humans on the SAT

After a hugely successful launch of its ChatGpT in November, OpenAI today announced the launch of the latest version of its primary large language model, GPT-4. Unlike its predecessors, OpenAI said the new GPT-4 is a large multimodal model that can solve difficult problems with greater accuracy, adding that GPT-4 is the company’s most advanced system to date, producing safer and more useful responses.
Thanks to its broader general knowledge and problem-solving abilities, the Microsoft-backed AI startup said the new GPT-4 exhibits “human-level performance” on many professional tests. In one test, OpenAI claimed that GPT-4 performed at the 90th percentile on a simulated bar exam, the 89th percentile on the SAT Math exam, and the 93rd percentile on an SAT reading exam.
The company also took to social media to announce the new release.
Announcing GPT-4, a large multimodal model, with our best-ever results on capabilities and alignment: https://t.co/TwLFssyALF pic.twitter.com/lYWwPjZbSg
— OpenAI (@OpenAI) March 14, 2023
ChatGPT-4 is also “larger” than previous versions. This mean means it has been trained on larger datasets and has more weights in its model file, which also makes it more expensive to run as well. Microsoft said on Tuesday that Bing’s AI chatbot also uses GPT-4.
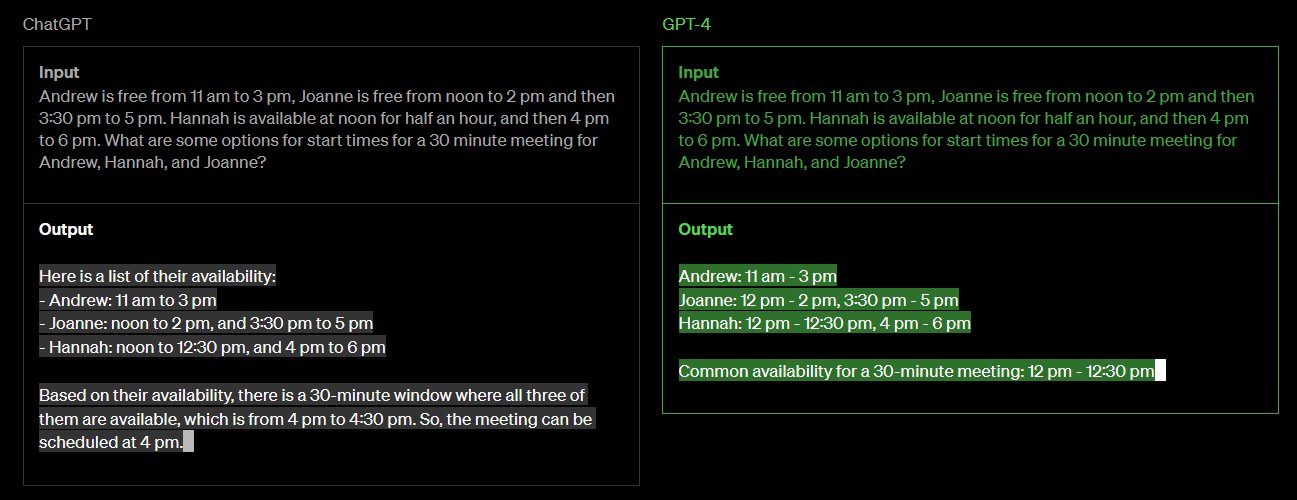
In a blog post on its website, OpenAI also shared a side-by-side comparison of ChatGPT and GPT-4 to show how GPT-4 surpasses ChatGPT in its advanced reasoning capabilities.
OpenAI also explained that it used Microsoft Azure to train the model. As we reported on multiple occasions, Redmond-based Microsoft a $1 billion in 2019 followed by another $10 billion in exchange for a 49% stake in the company.
In just two months after its launch, ChatGPT went from an obscure AI tool to reaching 100 million monthly active users in January, making it the fastest-growing consumer application in history. The sudden success of ChatGPT has put more pressure on other tech companies including Google, Baidu, and Alibaba, to launch their own ChatGPT-like tools.
Two years ago, OpenAI shocked the world with the launch of its Generative Pre-trained Transformer 3 (popularly known as GPT-3), an autoregressive language prediction model that uses deep learning to produce human-like text on demand.
OpenAI first described GPT-3 in a published a research paper published in May 2020. With a whopping 175 billion trainable parameters that require 800 GB of storage, GPT-3 has been dubbed the most powerful language model ever. Since then, GPT-3 has served as the underlying backbone for AI content platforms like Jasper.AI, which enables creators to create original content, and images 10 times faster than humans.
Generative Pre-training Transformer (GPT) is a type of language model developed by OpenAI. It is a neural network-based model that is trained to generate human-like text by predicting the next word in a sequence based on the words that come before it. ChatGPT and other generative AI tools use a large language model (LLM) technique to generate text in a chat-like or conversational style.
The popularity of OpenAI ChatGPT has now led to a boom in the adoption of generative artificial intelligence (AI) and big tech companies and small startups alike are in a race to integrate it into their products. Since its launch in November, ChatGPT has impressed many experts with its writing ability, software coding, proficiency in handling complex tasks, and its ease of use.
OpenAI says the new model will produce fewer factually incorrect answers, and in some cases, even perform better than humans on many standardized tests. However, OpenAI cautions that while the new software shows promise, it is not flawless and falls short of human capabilities in several scenarios.
A significant issue with the software is “hallucination,” which refers to its tendency to generate fabricated information. Furthermore, the software is not consistently reliable in terms of factual accuracy and may persist in asserting its correctness even when proven wrong.
“GPT-4 still has many known limitations that we are working to address, such as social biases, hallucinations, and adversarial prompts,” the company said in a blog post.
“In a casual conversation, the distinction between GPT-3.5 and GPT-4 can be subtle. The difference comes out when the complexity of the task reaches a sufficient threshold—GPT-4 is more reliable, creative, and able to handle much more nuanced instructions than GPT-3.5,” OpenAI added.

