Inside AI: Are LLMs like ChatGPT just Reddit wrappers, or UGC regurgitation machines?

A new Semrush study shows large language models like ChatGPT and Perplexity aren’t tapping hidden wells of knowledge—they’re acting as wrappers around user-generated content (UGC) from Reddit, Wikipedia, YouTube, and more.
On August 18, 2023, we published a piece titled ‘AI Wrappers: The Rise of AI Wrappers and the Challenges Ahead.’ In it, we examined how startups were building SaaS products on top of large language models (LLMs) like OpenAI’s ChatGPT. At the time, wrappers were seen as clever ways to package AI’s intelligence for new use cases.
Two years later, the story has taken an unexpected turn. The wrappers aren’t just startups’ AI SaaS products anymore. The LLMs themselves are looking like wrappers—this time around user-generated content (UGC) from platforms like Wikipedia and, most of all, Reddit.
LLMs Unmasked: Reddit Wrappers or True Intelligence?
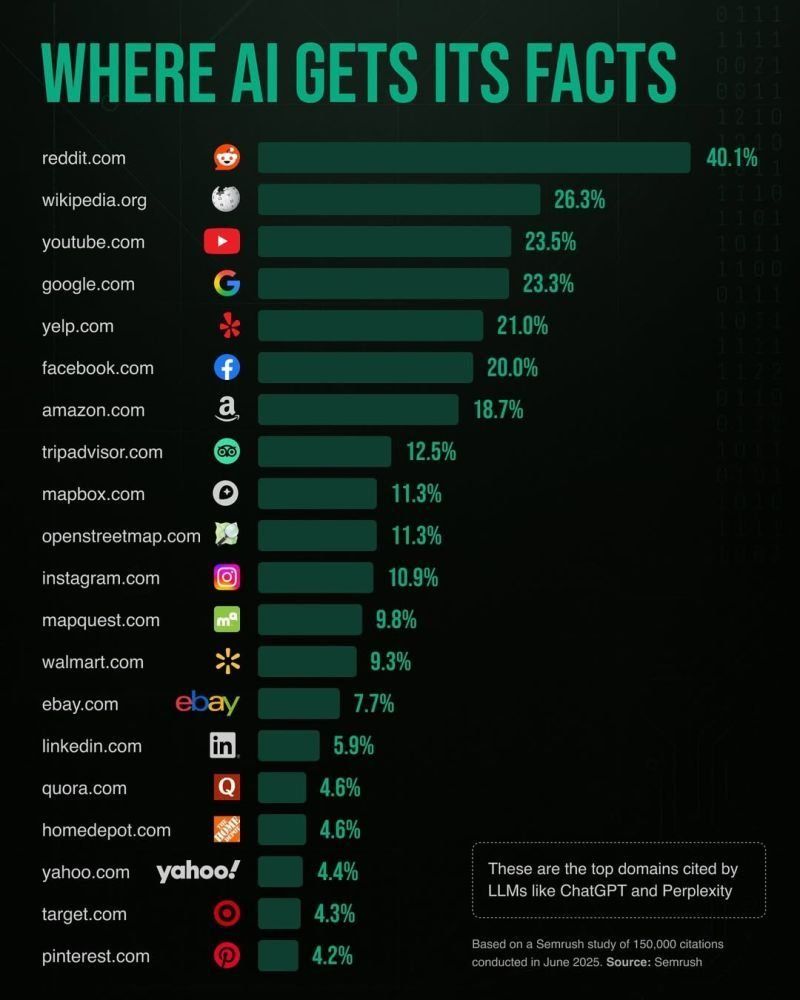
A new study from Semrush puts data behind the suspicion many have had: today’s AI systems don’t generate knowledge from thin air. They’re pulling from the same internet watering holes we do, and repackaging that content in a conversational tone. Reddit tops the charts by a wide margin, appearing in more than 40 percent of citations across ChatGPT, Perplexity, Google’s AI Mode, and AI Overviews. If your chatbot sounds like a Reddit thread, this is why.
“Today’s AI systems don’t generate knowledge from thin air. They’re pulling from the same internet watering holes we do, and repackaging that content in a conversational tone.”
Semrush’s research, published in June 2025, analyzed more than 150,000 citations pulled from four of the most widely used LLMs: ChatGPT, Perplexity, Google’s AI Mode, and AI Overviews. To stress-test the models, the team ran 5,000 randomly chosen keywords—ranging from informational to transactional queries—and tracked which domains the systems leaned on most often.
The results stripped away any mystique. Instead of serving as fountains of original thought, the models are more like curators with a preference for user chatter. Reddit dominated the pack with a staggering 40.1 percent citation frequency. Wikipedia landed in second place at 26.3 percent, followed by YouTube, Google, and Yelp. Facebook, Amazon, and TripAdvisor weren’t far behind, rounding out a top ten that leaned heavily on platforms built around community discussion and reviews.
Where AI Gets Its Facts: How ChatGPT, Perplexity, and Google AI Rely on Reddit for Answers
The study also revealed how each model behaves differently. Perplexity’s citations lined up closely with Google’s search results—91 percent domain overlap—making it feel less like a breakthrough and more like a souped-up search engine. ChatGPT showed weaker alignment with Google, resembling Bing’s historical citation patterns instead. Google’s own AI Mode took a broader approach, averaging seven unique domains per response and pulling frequently from mapping platforms like Mapbox and OpenStreetMap, even when those sites wouldn’t usually rank highly in a traditional search.
This paints LLMs less as engines of innovation and more as filters over familiar web terrain, with Reddit acting as the central hub of their collective “knowledge.”
Where AI Gets Its Facts (Credit: SemRush)
The Dark Side of LLMs: Biases, Misinfo, and Echo Chambers
Calling LLMs “Reddit wrappers” isn’t just a clever punchline—it highlights real risks. Heavy reliance on user-generated content means these systems inherit the same flaws that come with it: misinformation, bias, and the echo chamber effect.
Reddit’s strength is its scale and diversity, but it’s also a breeding ground for half-baked claims, unverified anecdotes, and viral myths. When LLMs absorb and recycle that material, the line between fact and fiction can blur. The danger isn’t theoretical. In past cases, ChatGPT has suggested mixing bleach and vinegar to purify water—a combination that actually creates toxic chlorine gas. The likely culprit? Bad advice scraped from online forums.
Bias is another layer. Reddit communities, like all online spaces, reflect the perspectives of their most active users. If those voices skew heavily toward certain demographics or viewpoints, the AI trained on them may amplify that tilt. Instead of broadening perspectives, the technology risks narrowing them, reinforcing the same blind spots already present in UGC.
Even seemingly neutral domains on the top-cited list come with caveats. Yelp and TripAdvisor, for example, are valuable for reviews, but they’re still subjective accounts shaped by individual experiences. Map platforms like OpenStreetMap rely on volunteer contributions that vary in accuracy. These inputs may work fine for restaurant suggestions or local tips, but when LLMs pull them into health, financial, or legal contexts, the consequences can get serious.
For anyone treating AI responses as authoritative, the study is a sobering reminder: the source material isn’t expert-reviewed knowledge, but a mosaic of crowd-sourced chatter dressed up in polished sentences.
What This Means for the Future
As AI systems weave deeper into daily life, the Semrush study underscores an uncomfortable truth: the intelligence of LLMs is only as strong as the content they’re built on. Right now, that foundation leans heavily on Reddit threads, Wikipedia edits, Yelp reviews, and other forms of user-generated content.
This isn’t inherently bad—forums and community-driven sites capture real human experience at scale—but it does blur the boundary between expert knowledge and collective opinion. When AI repackages that mix with the confidence of an oracle, it raises the stakes for curation.
Some companies are already experimenting with fixes. Perplexity’s closer alignment with search results makes it feel like a next-gen search engine, while xAI has pitched real-time sourcing from X posts as a way to bring freshness and transparency. Google’s approach of citing more unique domains suggests an effort to broaden inputs. But none of these efforts change the fact that bias, misinformation, and uneven quality remain built into the pipeline.
The takeaway isn’t that AI should be dismissed, but that its users—and builders—should treat the outputs less as revelation and more as aggregation. The future of trustworthy AI won’t come from hiding the sources, but from expanding and vetting them. Until then, when ChatGPT answers your question, remember: you may just be reading a Reddit thread in better grammar.
Trending Now



