OpenAI launches first open weight models in years with gpt‑oss‑120b and 20b

After years of closed AI, OpenAI has quietly rolled out its first openly accessible language models in more than five years: gpt‑oss‑120b and gpt‑oss‑20b. These models aren’t fully open source in the classic sense, but they do let anyone download the trained model weights and run them locally, fine‑tune them, or repurpose them—as long as you comply with the Apache 2.0 license.
OpenAI CEO Sam Altman shared the news in a post on X: “gpt-oss is out! we made an open model that performs at the level of o4-mini and runs on a high-end laptop (WTF!!)(and a smaller one that runs on a phone). super proud of the team; big triumph of technology.”
Key Highlights
-
Two models available: gpt‑oss‑120b and gpt‑oss‑20b.
-
Performance: The 120b model rivals OpenAI’s proprietary o4‑mini, while the smaller model performs at a level similar to o3‑mini.
-
Hardware requirements: The 120b model can run on a single high‑end NVIDIA GPU. The 20b model is lightweight enough to run on many consumer laptops with 16 GB RAM or even smartphones.
-
Licensing and access: Both are released under the Apache 2.0 license, allowing commercial use and redistribution. They can be downloaded from major AI model hubs and cloud platforms.
-
Cloud integration: Available on AWS Bedrock, SageMaker, Azure, and Databricks. AWS reports the 120b model offers cost and performance advantages over rival models from Google, DeepSeek, and others.
-
Safety measures: OpenAI delayed the release twice to conduct extensive safety tests and external audits before launch.
Open Models by OpenAI: Why It Matters

This is OpenAI’s first open‑weight release in more than five years, signaling a strategic shift in how the company shares its technology. By making the weights available, OpenAI allows developers, researchers, and even hobbyists to run advanced language models locally or in the cloud without relying on proprietary APIs.
The move also places OpenAI in more direct competition with other open‑weight leaders like Meta’s LLaMA, DeepSeek‑R1, Alibaba’s Qwen, and Mistral. It addresses the growing demand for AI models that offer transparency, customizability, and independence from closed platforms.
For smaller teams and startups, the ability to fine‑tune or repurpose these models under a permissive license means they can build high‑level AI applications without the infrastructure costs of training from scratch.
The launch marks a pivot from OpenAI’s recent closed‑shadowed strategy, where most models hidden behind ChatGPT never made their internal weights public. With GPT‑oss, you now have two language systems that support step‑by‑step reasoning, tool use like code execution or browsing, and a switchable reasoning effort mode (low, medium, or high) that trades latency for accuracy.
OpenAI gpt‑oss‑120b

The larger model, gpt‑oss‑120b, clocks in at around 117–120 billion parameters, but thanks to a mixture‑of‑experts architecture and efficient quantization, only around 5 billion parameters are active per token. The smaller, gpt‑oss‑20b, requires just over 16 GB of RAM—enough to run on many modern laptops or even powerful smartphones.
OpenAI tested both heavily before launch. Rather than merely assuming safe use, they ran adversarial simulations—learning how a bad actor might fine‑tune the weights to generate harmful content. Those tests were reviewed by external experts, and the models didn’t reach problematic levels of capability in areas like bioweapons or cybersecurity. OpenAI delayed the release twice to get these assessments right.
In benchmarks, gpt‑oss‑120b often rivals OpenAI’s closed proprietary o4‑mini model, and outperforms o3‑mini. The 20B model lands near O3-mini’s territory. They also hold up well in tool‑using and reasoning gaps, though they show slightly more hallucination in certain factual tasks than the highest-end closed systems.
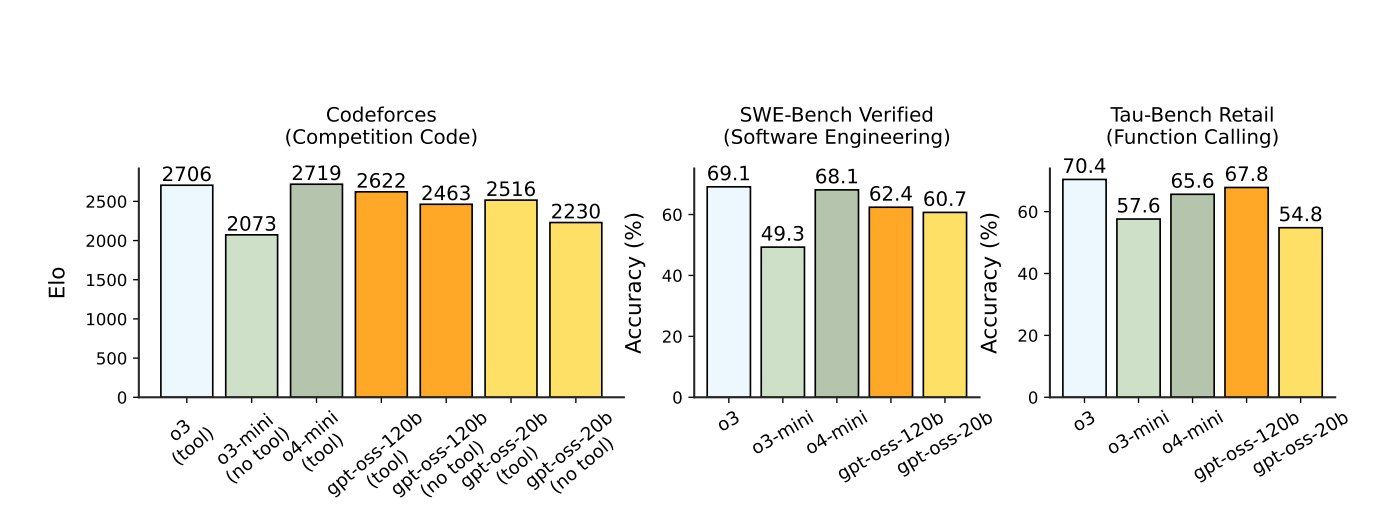
This release positions OpenAI more directly against other open‑weight heavyweights: Meta’s LLaMA 4, Chinese giants like DeepSeek‑R1 and Alibaba’s Qwen, as well as Europe’s Mistral models. All of those use similarly permissive licensing like Apache 2.0. OpenAI made clear it hopes this approach lowers the barrier for developers and researchers globally—especially amid growing concern about dependence on proprietary AI stacks.
From a practical standpoint, developers can get the models from Hugging Face or run them in the cloud via AWS Bedrock, SageMaker, Azure, or Databricks. AWS even highlighted that gpt‑oss‑120b delivers up to three times the cost efficiency of Google Gemini and outshines DeepSeek‑R1 and o4‑mini in live production comparisons.
Even though the training code and dataset remain private, the fact that OpenAI released trained weights under Apache 2.0 makes these models unusually open for the company. They aren’t fully open‑source, but they bring far more visibility—and control—to developers than previous releases.
Comparison Table
| Model Variant | Size (Parameters) | Comparable Closed Model | Runs Locally? | Ideal Use Case |
|---|---|---|---|---|
| gpt‑oss‑120b | ~120 billion | o4‑mini | Yes, on a high‑end GPU | High‑performance reasoning and tool use |
| gpt‑oss‑20b | ~20 billion | o3‑mini | Yes, on laptops/phones | Lightweight AI tasks, mobile deployment |
Trending Now



