Alibaba’s Aegaeon cuts Nvidia GPU usage by 82%, doing to AI hardware what DeepSeek did to software

US tech companies have been pouring billions into GPUs and data centers to keep their AI models running. But while the race for more hardware continues in Silicon Valley, Alibaba may have just found a way to need less.
The Chinese tech giant introduced a new system called Aegaeon that slashed the number of Nvidia GPUs required to run large language models by an eye-opening 82%. The breakthrough echoes what DeepSeek did for AI software — this time, it’s hardware efficiency rewriting the rules.
According to a report from South China Morning Post, Aegaeon allows a single GPU to serve multiple AI models at once, drastically reducing the total hardware needed. In testing, the system cut the number of Nvidia H20 GPUs required to serve dozens of models — some with up to 72 billion parameters — from 1,192 to just 213.
Alibaba Challenges Nvidia Dependence With Aegaeon — 82% Fewer Nvidia GPUs Needed
The results were presented at the 31st Symposium on Operating Systems Principles (SOSP) in Seoul, South Korea. “Aegaeon is the first work to reveal the excessive costs associated with serving concurrent LLM workloads on the market,” the researchers from Peking University and Alibaba Cloud wrote.
Alibaba Cloud, the company’s AI and cloud services arm, worked with researchers to develop the new multi-model serving system. Its CTO, Zhou Jingren, is one of the paper’s authors. The study, also published on ACM.org, highlighted that “Aegaeon reduces the number of GPUs required for serving these models from 1,192 to 213, highlighting an 82% GPU resource saving.”
What is Aegaeon?
Aegaeon is Alibaba’s new multi-model serving system built to make GPU usage far more efficient. Instead of assigning one model to one GPU, Aegaeon pools computing resources so multiple large language models can share the same GPU at once.
It does this by performing auto-scaling at the token level — meaning Aegaeon decides how to allocate GPU power as each token (or piece of generated text) is processed. This fine-grained scheduling lets the system balance workloads in real time, maintaining high performance without over-provisioning hardware.
The researchers said Aegaeon cuts auto-scaling overhead by 97% through smarter memory management, component reuse, and synchronized cache handling. In testing, the system sustained 2–2.5× higher request arrival rates and 1.5–9× greater goodput than other solutions.
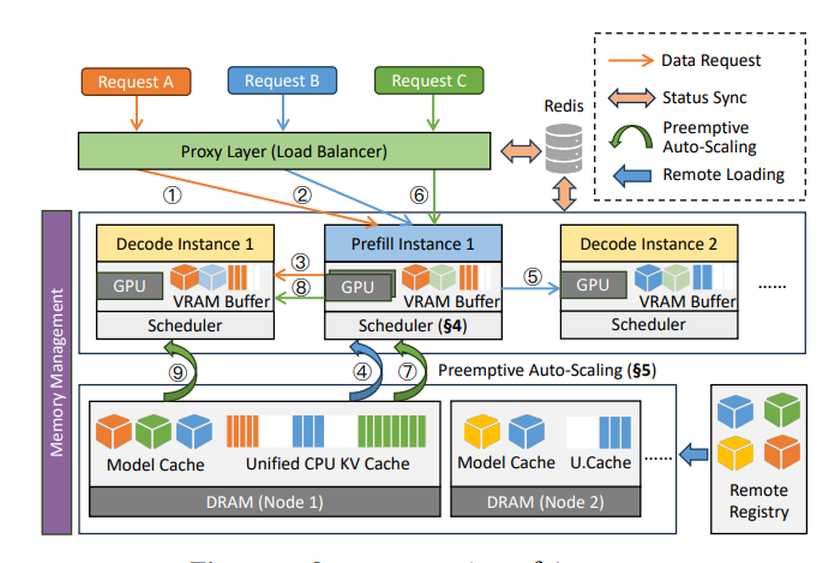
System overview of Aegaeon (Credit: Alibaba and ACM.org)
Aegaeon has already been beta deployed in Alibaba Cloud’s model marketplace, where it serves dozens of models in production. Results show it reduced the number of Nvidia GPUs required from 1,192 to 213, saving 82% of GPU resources.
The research points to a clear inefficiency across the AI industry. Cloud providers like Alibaba Cloud and ByteDance’s Volcano Engine must juggle thousands of AI models at the same time. But usage data shows that only a few — such as Alibaba’s Qwen and DeepSeek — handle the majority of requests, leaving many others idle and wasting GPU power.
The researchers found that nearly 17.7% of GPUs were serving just 1.35% of requests — a massive drain on resources. Aegaeon changes that equation.
The system performs what the team calls “auto-scaling at the token level,” allowing a GPU to switch between models mid-generation. That means one GPU can handle multiple conversations at once, smoothly shifting between tasks without delay. With this approach, a single GPU can support up to seven AI models simultaneously, compared to only two or three under existing systems, and cuts model-switching latency by 97%.
In their conclusion, the researchers wrote:
“This paper presents Aegaeon, a system that pools GPU resources to concurrently serve numerous LLMs on the market. By enabling highly efficient auto-scaling at the token level, Aegaeon achieves 2∼2.5× higher request arrival rates or 1.5∼9× higher goodput compared to alternative solutions. Aegaeon has been deployed in production serving tens of models, reducing overall GPU usage by 82%.”
Aegaeon’s arrival signals more than a technical optimization — it represents a strategic rethink of how AI workloads are managed. While American firms keep scaling up, Alibaba is scaling smart.
And if DeepSeek marked the turning point for AI software efficiency, Aegaeon may do the same for AI hardware.
Trending Now

Top Tech News Today, March 10, 2026


