DeepSeek unveils ‘Sparse Attention,’ a breakthrough next-gen AI model for faster, cheaper long-context processing

Months after rattling the AI market with its R1 model, praised for outpacing popular rivals at a fraction of the cost, Chinese AI startup DeepSeek is back in the spotlight. The Hangzhou-based company has introduced a new experimental system, DeepSeek-V3.2-Exp, which is built around a technique it calls “Sparse Attention.” The move, first reported by Bloomberg, signals what the company describes as an “intermediate step” toward a next-generation architecture.
DeepSeek has been building a reputation as one of China’s most ambitious AI players, pairing technical ambition with secrecy. With V3.2-Exp, it’s targeting one of the thorniest challenges in large language models: efficiency at scale, particularly in handling extended text. The system builds directly on DeepSeek-V3.1-Terminus and introduces Sparse Attention, a method that trims the computational overhead of long-context tasks while keeping output quality intact.
“DeepSeek updated an experimental AI model Monday in what it called a step toward next-generation artificial intelligence. The secretive Chinese startup outlined the DeepSeek-V3.1-Exp platform, explaining it uses a new technique it calls DeepSeek Sparse Attention or DSA, according to a post on its Hugging Face page,” Bloomberg reported.
DeepSeek V3.2 AI Model’s Sparse Attention Method
Sparse Attention replaces the traditional brute-force approach of transformers—where every token is forced to interact with every other token—with something more selective. A “lightning indexer” quickly scores past tokens and ranks their importance, keeping only the most relevant for each query.
This shortcut cuts down the quadratic workload, enabling up to a 64x speedup when dealing with sequences as long as 128,000 tokens. The method combines coarse-grained token compression with fine-grained selection, ensuring the model doesn’t lose track of broader context. DeepSeek says this is distinct from its earlier attempt, Native Sparse Attention, launched earlier this year, and can even be retrofitted onto pre-trained models.
In benchmarks, V3.2-Exp holds its ground against the company’s previous version. On reasoning, coding, and tool-use tests, the differences were minor—often within a point or two—while efficiency gains were striking. The model ran 2–3 times faster on long-context inference, cut memory usage by 30–40 percent, and improved training efficiency by half. For developers, that means faster responses, lower infrastructure costs, and a smoother path to deployment.
“Introducing DeepSeek-V3.2-Exp — our latest experimental model! Built on V3.1-Terminus, it debuts DeepSeek Sparse Attention(DSA) for faster, more efficient training & inference on long context. Now live on App, Web, and API. API prices cut by 50%+!,” DeepSeek said in a post on X.
DeepSeek-V3.2-Exp Performance and Benchmarks
DeepSeek-V3.2-Exp, with approximately 671 billion parameters, was trained under configurations aligned with V3.1-Terminus to isolate the impact of DSA. Benchmarks across reasoning, coding, and agentic tool use demonstrate parity or slight improvements:
| Benchmark Category | Specific Test | V3.1-Terminus Score | V3.2-Exp Score |
| Reasoning (w/o Tool Use) | MMLU-Pro | 85.0 | 85.0 |
| GPQA-Diamond | 80.7 | 79.9 | |
| AIME 2025 | 88.4 | 89.3 | |
| Codeforces | 2046 | 2121 | |
| Agentic Tool Use | BrowseComp | 38.5 | 40.1 |
| SimpleQA | 96.8 | 97.1 | |
| SWE-bench Multilingual | 57.8 | 57.9 |
These results indicate DSA introduces minimal quality loss—often within 1-2 points—while delivering substantial efficiency gains: 2-3x faster inference for long contexts, 30-40% reduced memory usage, and up to 50% improved training efficiency. In practical terms, this translates to faster pre-filling and decoding phases, making the model more viable for real-world deployments.
DeepSeek has made the model accessible on Hugging Face under an MIT license, with CUDA kernels and optimizations on GitHub. It works with hardware like NVIDIA’s H100 GPUs, though the company recommends one for testing and eight for production workloads. Deployment options include Hugging Face transformers, SGLang, and vLLM.
The company is also slashing costs. API prices have been cut by more than 50 percent, with inputs as low as $0.07 per million tokens under cache hits. That puts DeepSeek among the cheapest large-scale AI providers, a move that could appeal to startups and enterprises alike. The model is already live on DeepSeek’s app, web platform, and API, with community feedback open through October 15.
The timing matters. Global AI leaders are pouring billions into resource-heavy systems, while DeepSeek is betting that efficiency will define the next wave. By squeezing more value out of long-context processing, Sparse Attention positions the company to compete not just on performance but on economics. Industry voices on X have already suggested that its approach could make intelligence “almost too cheap to meter.”
DeepSeek’s strategy—tight-lipped, experimental, and unapologetically aggressive on efficiency—keeps it firmly in the global AI race. With V3.2-Exp, the company isn’t just iterating on past work; it’s laying the groundwork for what it sees 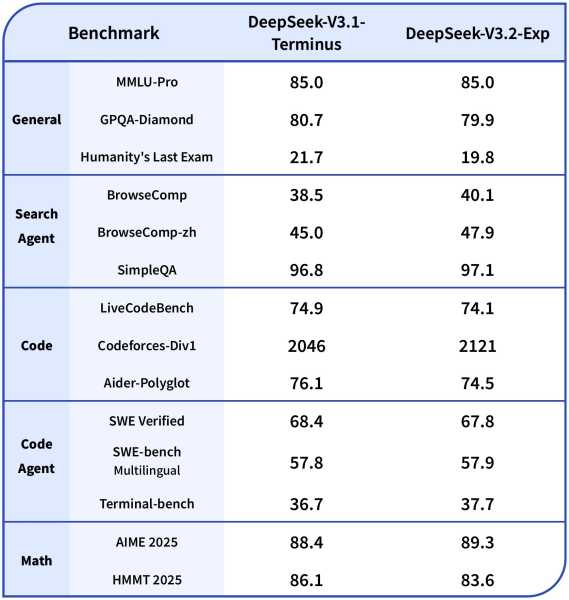 as the future of large-scale AI.
as the future of large-scale AI.
Trending Now

Top Tech News Today, March 25, 2026


