Pulling timely and relevant data for AI agents using Bright Data

AI agent adoption is skyrocketing in all verticals, as part of the shift towards autonomous AI systems that can complete complex tasks without human involvement. Many organizations are benefiting from the value they can deliver, but there’s a significant obstacle in the path to success.
It’s the same one that’s hobbled numerous AI projects over the years: access to data. But this time, the demands are greater. AI agents require a dynamic data retrieval solution that’s optimized for multi-step workflows, knows how to translate natural language queries into specific data queries, and can scale up automatically to source and process massive loads of relevant information.
To be effective, the agents need to accomplish all of this in real time. It’s a lot to ask, especially on top of the “basics” of verified, reliable, recent and accurate data that doesn’t fall foul of data privacy or industry-specific regulations.
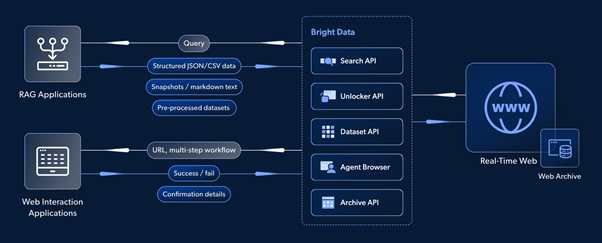
Bright Data offers robust data sourcing solutions, with compliance and transparency baked in, auto-scaling to power an unlimited number of AI agents. The system is designed to meet the complex needs of agentic workflows, understanding context and interpreting data queries to deliver relevant, up to date information from every corner of the open web.
Instant responsiveness
Real time has become a buzz term for AI projects, but it’s essential for AI agents. Even a task that seems simple in human terms, like buying a concert ticket, requires immediate knowledge about changes in pricing, seating options, and other factors.
Bright Data meets this demand easily, with user-friendly APIs, headless and serverless browsers, and hordes of residential IP proxies that can be up and running in minutes. Its low-latency response processing delivers relevant search results in real time, preventing delayed inputs and ensuring that agentic systems can move smoothly through each step of their workflows.
The auto-scaling browser infrastructure is optimized for the needs of LLMs and agents, and it can expand at will as your data needs increase. Bright Data can handle unlimited concurrent sessions and adapts instantly to current events and trends, eliminating lags and making sure that information is always relevant to the moment.
Full awareness
AI agents handle more complex scenarios than old-school chatbots, and that demands a richer, contextual understanding of user demands and circumstances. At the same time, as users rely on them more for the autonomous execution of strategic tasks, hallucination and bias become serious threats.
The best way to combat these ills is through broad, diverse datasets, which are best found across the internet. Bright Data steps up to the plate with powerful proxies that can fully unlock any public website, overcoming restrictions and avoiding bot-blockers to extract all the data within any target domain.
There’s no limit to the amount of data that it can source, extract, and return. Unlike some web data retrieval solutions, Bright Data can be integrated into workflow processes that allow systems to cope with unstructured data as well as structured data. This way, AI teams can enrich datasets to make up for missing details, ensuring that AI agents always gain a complete understanding of the information required.
Accurate understanding
AI agents have to be able to process complicated, multi-step jobs, which often span diverse topics and domains. Success requires data retrieval systems that can source information that’s appropriate for each specific use case.
Natural language queries are frequently vague, using unclear syntax and ambiguous wording. Thanks to the profusion of jargon and professional terminology, the same term can mean very different things in different contexts. For example, a query about blocking can refer to cybersecurity, design, construction, or ballet.
Bright Data’s customizable sourcing tools direct your AI agent to the sources that are most suitable to the topic, turning user queries into precise search terms and delivering the data that underpins relevant responses.
The solution simulates genuine user behavior to acquire more accurate results, and can extract data directly from search engine result pages as well as specific web pages. Full script-based control lets you automate browsing to discover and draw out data from any target domain.
True transparency
Compliance, trust, and ethical behavior are growing challenges for every AI and data project. Due to their complexity, AI agents can make it harder to meet these needs. Bright Data’s data retrieval system has privacy and security guardrails baked in, pulling only data that is licensed, trustworthy, and doesn’t breach copyright legislation.
The hard-coded transparency helps users to maintain compliance with data privacy and data sourcing regulations, and to meet industry-specific requirements for fields like finance or health.
By sticking to verifiable sources and automatically compiling audit logs, Bright Data helps improve auditability and promote trust.
Web data is a vital ingredient in AI agent success
Diverse, trusted, real-time data is the fuel that keeps AI agents efficient and effective. With timely, trusted data, you can field AI agents that deliver lag-free, accurate responses and avoid problems like bias and non-compliance. Bright Data delivers the data you need, fast and friction-free, so your AI agents can keep running smoothly.
Trending Now



