OpenAI launches next-gen audio AI models: Smarter speech-to-text and expressive AI voices

OpenAI just dropped a fresh batch of audio models, shaking up how voice AI works. The new lineup of audio models is designed to push voice AI forward. The new releases include text-to-speech and speech-to-text models that push things forward in voice recognition and generation.
The release includes gpt-4o-mini-tts, a text-to-speech model that offers precise control over tone and timing, and two advanced speech-to-text models, gpt-4o-transcribe and gpt-4o-mini-transcribe, which outperform Whisper in handling diverse accents and noisy environments.
These models are now available through OpenAI’s API and Agents SDK, making it easier for developers to build sophisticated voice-powered applications. OpenAI has also launched OpenAI FM, a platform for testing its text-to-speech models, and introduced a contest to inspire creative uses of the technology. The announcement has generated strong interest from developers and the tech community, highlighting its potential to reshape voice-driven software.
Text-to-Speech and Transcription Just Got an Upgrade
The latest models include gpt-4o-mini-tts for text-to-speech, built to handle nuanced speech with better control over tone and timing. Developers can fine-tune the way words are spoken, opening up possibilities for more expressive AI-driven voices.
For speech-to-text, OpenAI introduced gpt-4o-transcribe and gpt-4o-mini-transcribe. Both models outperform previous versions, including Whisper, by improving transcription accuracy in noisy settings and across different accents. They handle real-world conversations more effectively, making them useful for customer service, content creation, and accessibility tools.
Bringing AI Speech to More Developers
OpenAI is rolling these models into its API, making them available for developers to plug into their applications. Pricing is competitive:
- gpt-4o-transcribe: $6 per million audio input tokens (~$0.006 per minute)
- gpt-4o-mini-transcribe: $3 per million audio input tokens (~$0.003 per minute)
- gpt-4o-mini-tts: $0.60 per million text input tokens and $12 per million audio output tokens (~$0.015 per minute)
These updates streamline the process of integrating high-quality speech processing into apps, whether for live customer support, automated note-taking, or interactive voice assistants.
OpenAI FM and Community Engagement
To show what these models can do, OpenAI has launched OpenAI.fm, a platform where users can test text-to-speech capabilities. Alongside this, they’ve kicked off a contest to encourage creative applications of their latest tech. Expect to see developers experimenting with new ways to use AI voices, from personalized assistants to audio content generation.
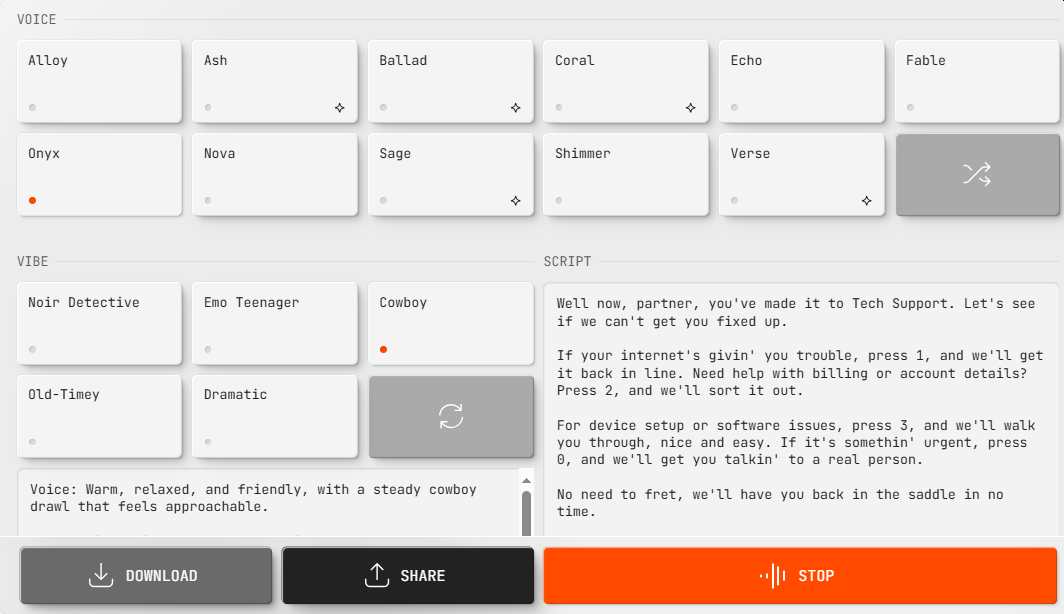
An interactive demo for developers to try the new text-to-speech model in the OpenAI API. (Credit: OpenAI)
AI Voice Agents
With its new audio models, OpenAI just raised the bar for voice agents—and the upgrade is easy to hear.
Voice agents are those digital assistants you talk to, like Alexa, Siri, or the voice that answers when you call customer support. You speak, they respond. They can answer questions, play music, control your smart home, set reminders, or handle basic support calls.
The tech behind them blends speech recognition, natural language processing, and text-to-speech. That’s how they understand what you’re saying, figure out what you mean, and talk back in a way that feels human. Machine learning helps them get better over time.
What OpenAI has done is strip out the robotic feel. The new models handle noisy environments more smoothly, speak with a more natural rhythm, and can shift their tone depending on the moment—calm and empathetic during support calls, upbeat and animated when reading the news.
According to OpenAI, the three new state-of-the-art audio models in the API include: “Two speech-to-text models—outperforming Whisper, a new TTS model—you can instruct it *how* to speak, and the Agents SDK now supports audio, making it easy to build voice agents.”
Three new state-of-the-art audio models in the API:
🗣️ Two speech-to-text models—outperforming Whisper
💬 A new TTS model—you can instruct it *how* to speak🤖 And the Agents SDK now supports audio, making it easy to build voice agents.
Try TTS now at https://t.co/MbTOlNYyca.
— OpenAI Developers (@OpenAIDevs) March 20, 2025
Early Reactions and Industry Impact
The launch has been well received, especially among developers looking for better transcription and voice synthesis options. Some early adopters, like EliseAI, have already integrated OpenAI’s text-to-speech model into their property management platform, reporting more natural and expressive voice interactions.
OpenAI isn’t stopping here. The company is working on expanding its speech technology with more voice options and eventually bringing AI-driven conversations closer to human-like exchanges. With big moves in AI-generated audio, the competition in voice technology is heating up.
Trending Now

Top Tech News Today, March 25, 2026


