ByteDance launches OmniHuman-1: AI that transforms photos into lifelike human videos

ByteDance, the parent company of TikTok, has introduced OmniHuman-1, an AI model capable of transforming a single image and an audio clip into stunningly lifelike human videos. The level of realism is so precise that distinguishing its output from actual footage is becoming increasingly difficult.
OmniHuman-1 can generate fluid, natural motion across any aspect ratio or body proportion, ensuring seamless adaptation to different formats. With just one image and an audio track, it produces remarkably authentic human videos, capturing facial expressions, gestures, and speech synchronization with incredible accuracy. While the technology has drawn attention to its capabilities, it is not currently available for public use or download.
According to the information shared on the project page on Github, OmniHuman is an advanced AI framework designed to create human videos from a single image using motion cues like audio, video, or a combination of both. Unlike previous models that struggled with data limitations, OmniHuman uses a multimodal training strategy to improve accuracy and realism, even with minimal input. The system works with images of any aspect ratio—portraits, half-body, or full-body—delivering highly lifelike results across different formats.
“We propose an end-to-end multimodality-conditioned human video generation framework named OmniHuman, which can generate human videos based on a single human image and motion signals (e.g., audio only, video only, or a combination of audio and video),” ByteDance researchers said in a post on GitHub.
ByteDance claimed that OmniHuman significantly outperforms existing methods, especially in generating realistic human motion from audio alone.
OmniHuman Video Generation Stages
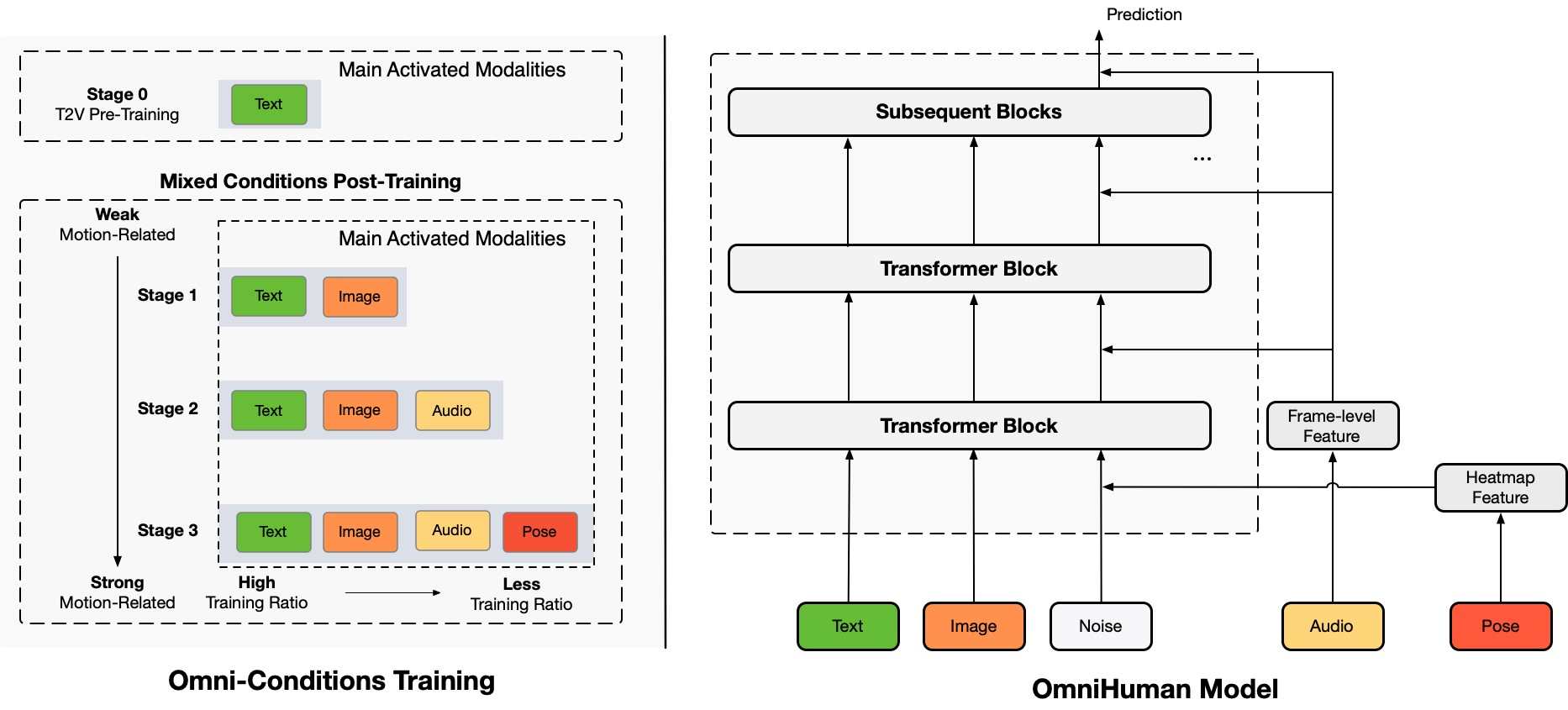
How OmniHuman-1 Works
OmniHuman-1 is built on 19,000 hours of video training data, allowing it to analyze a photo, process motion cues, and animate the subject with natural expressions, speech synchronization, and body movements. The AI breaks it down into two steps:
- Motion Processing – It compresses movement data from sources like audio and text prompts.
- Refinement – It fine-tunes the animation by comparing its output against real video footage to ensure accuracy.
One standout feature is its ability to adjust aspect ratios and body proportions, meaning it can generate videos that fit different formats while maintaining realistic motion. It even works with non-human figures, including cartoon characters and complex poses.

Click to watch the videos
Demos That Blur the Line Between AI and Reality
ByteDance hasn’t released OmniHuman-1 to the public, but early demos are making waves online. One clip shows a 23-second video of Albert Einstein giving a speech, with movements and expressions that look eerily real.
ByteDance, the company behind TikTok has just announced OmniHuman-1, a revolutionary video model.
With just one image & an audio track it can generate hyper-realistic human videos, seamlessly adapting to any aspect ratio or body shape.
Example: pic.twitter.com/SMICUC2U6a
— Brian Roemmele (@BrianRoemmele) February 5, 2025
At the same time, the technology is sparking serious concerns. As more U.S. states pass laws against AI-generated impersonations, distinguishing real content from synthetic media is becoming an increasingly urgent challenge. AI tools like this could redefine content creation, but they also open the door to ethical and regulatory debates that still lack clear solutions.
What’s Next?
OmniHuman-1 has set a new benchmark for AI-generated video. The ability to create lifelike animations from a single image is no longer a futuristic concept—it’s here. The bigger question is whether the world is ready for it.
Trending Now

Top Tech News Today, March 25, 2026


