Google launches AI-powered video editor Dreamix for creating and editing videos, and animating images

While OpenAI ChatGPT is sucking up all the oxygen out of the 24-hour news cycle, Google has quietly unveiled a new AI model that can generate videos when given video, image, and text inputs. The new Google Dreamix AI video editor now brings generated video closer to reality.
According to the research published on GitHub, Dreamix edits the video based on a video and a text prompt. The resulting video maintains its fidelity to color, posture, object size, and camera pose, resulting in a temporally consistent video. At the moment, Dreamix cannot generate videos from just a prompt, however, it can take existing material and modify the video using text prompts.
Google uses video diffusion models for Dreamix, an approach that has been successfully applied for most of the video image editing we see in image AIs such as DALL-E2 or the open-source Stable Diffusion.
The approach involves heavily reducing the input video, adding artificial noise, and then processing it in a video diffusion model, which then uses a text prompt to generate a new video from it that retains some properties of the original video and re-renders others according to the text input.
The video diffusion model offers a promising future that may usher in a new era for working with videos.

For example, in the video below, Dreamix turns the eating monkey (left) into a dancing bear (right) given the prompt “A bear dancing and jumping to upbeat music, moving his whole body.“
In another example below, Dreamix uses a single photo as a template (as in image-to-video) and an object is then animated from it in a video via a prompt. Camera movements are also possible in the new scene or a subsequent time-lapse recording.
In another example, Dreamix turns the orangutan in a pool of water (left) into an orangutan with orange hair bathing in a beautiful bathroom.
“While diffusion models have been successfully applied for image editing, very few works have done so for video editing. We present the first diffusion-based method that is able to perform text-based motion and appearance editing of general videos.”
According to the Google research paper, Dreamix uses a video diffusion model to combine, at inference time, the low-resolution spatiotemporal information from the original video with new, high-resolution information that it synthesized to align with the guiding text prompt.”
Google said it took this approach because “obtaining high-fidelity to the original video requires retaining some of its high-resolution information, we add a preliminary stage of finetuning the model on the original video, significantly boosting fidelity.”
Below is a video overview of how Dreamix works.
How Dreamix Video Diffusion Models Work
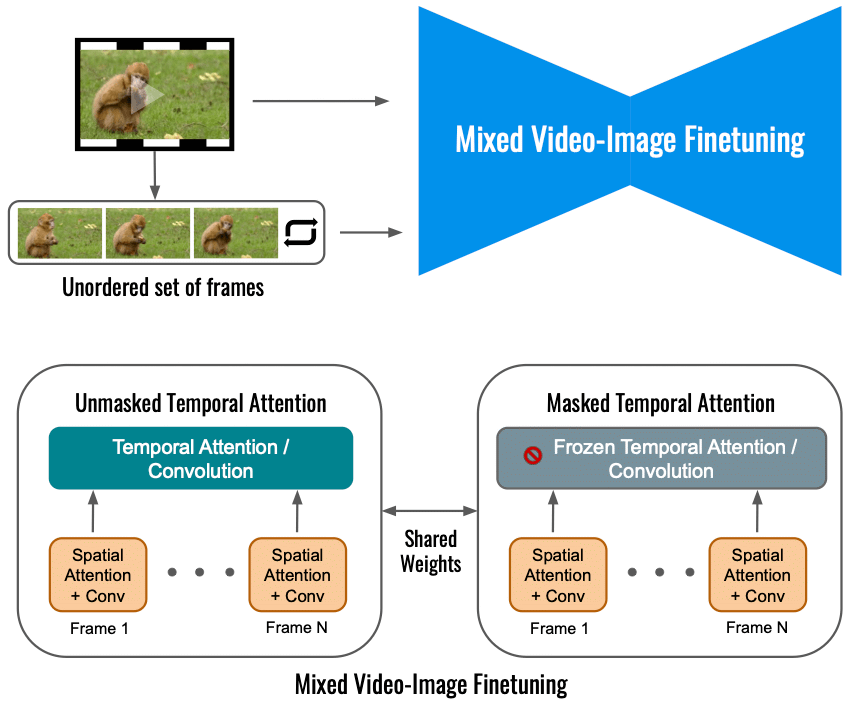
According to Google, finetuning the video diffusion model for Dreamix on the input video alone limits the extent of motion change. Instead, we use a mixed objective that besides the original objective (bottom left) also finetunes on the unordered set of frames. This is done by using “masked temporal attention”, preventing the temporal attention and convolution from being finetuned (bottom right). This allows adding motion to a static video.
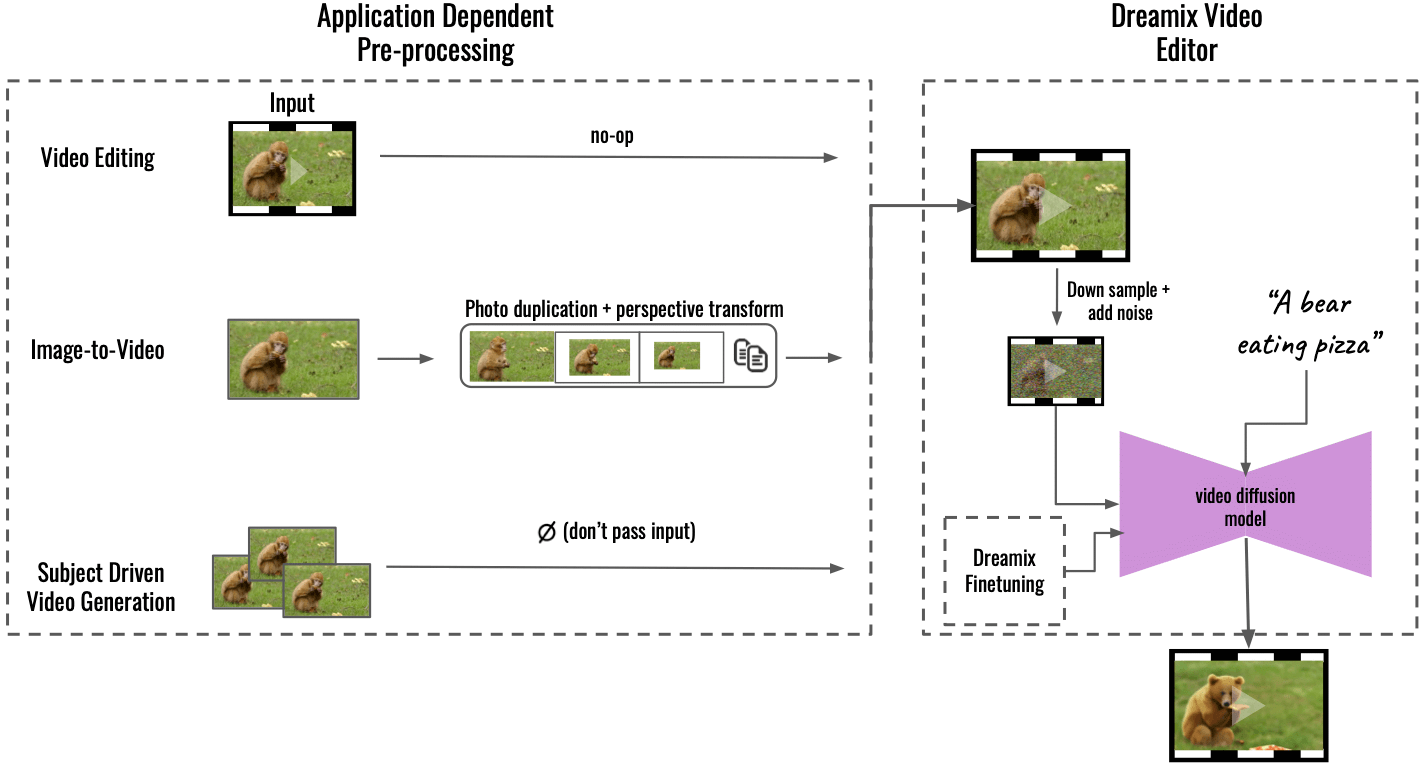
“Our method supports multiple applications by application-dependent pre-processing (left), converting the input content into a uniform video format. For image-to-video, the input image is duplicated and transformed using perspective transformations, synthesizing a coarse video with some camera motion. For subject-driven video generation, the input is omitted – finetuning alone take care of the fidelity. This coarse video is then edited using our general “Dreamix Video Editor“ (right): we first corrupt the video by downsampling followed by adding noise. We then apply the finetuned text-guided video diffusion model, which upscales the video to the final spatiotemporal resolution,” Dream wrote on GitHub.
You can read the research paper below.
Google DreamixTrending Now



