Cloudflare outage takes down a large portion of the internet; caused by bad software deployment
Cloudflare was down today taking a portion of the Internet with it. In a blog post on its website, Cloudflare said was cause by bad software deployment. Cloudflare co-founder and CEO Matthew Prince said a “massive spike in CPU usage” was to blame for the widespread outages and that the issue appears to have been mitigated. The company also expressed the outage was not an attack as some have speculated on social media.
“For about 30 minutes today, visitors to Cloudflare sites received 502 errors caused by a massive spike in CPU utilization on our network. This CPU spike was caused by a bad software deploy that was rolled back. Once rolled back the service returned to normal operation and all domains using Cloudflare returned to normal traffic levels,” the company said.
Founded ten years agor, Cloudflare is US company that provides content delivery network (CDN) services, DDoS mitigation, Internet security and distributed domain name server services. Cloudflare’s services sit between the visitor and the Cloudflare user’s hosting provider, acting as a reverse proxy for websites.
CloudFlare added: “This was not an attack (as some have speculated) and we are incredibly sorry that this incident occurred. Internal teams are meeting as I write performing a full post-mortem to understand how this occurred and how we prevent this from ever occurring again.”
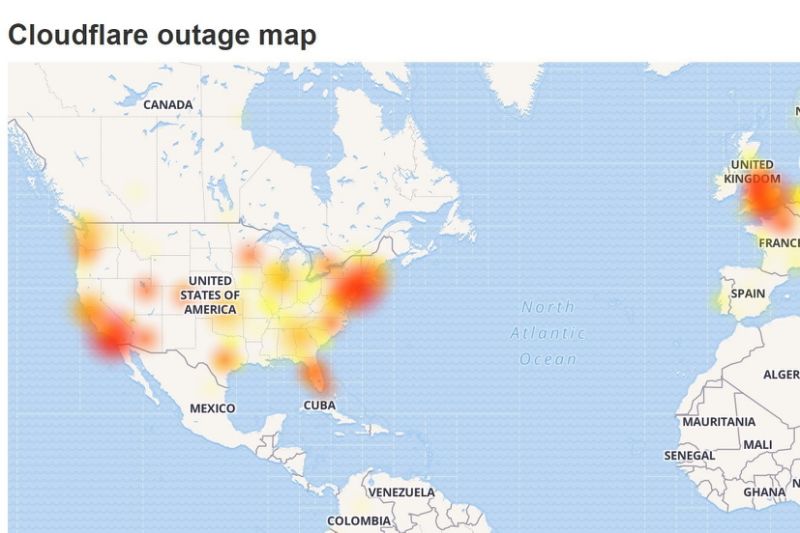
Below is an update released by CloudFlare at 2009 UTC:
“Starting at 1342 UTC today we experienced a global outage across our network that resulted in visitors to Cloudflare-proxied domains being shown 502 errors (“Bad Gateway”). The cause of this outage was deployment of a single misconfigured rule within the Cloudflare Web Application Firewall (WAF) during a routine deployment of new Cloudflare WAF Managed rules.
The intent of these new rules was to improve the blocking of inline JavaScript that is used in attacks. These rules were being deployed in a simulated mode where issues are identified and logged by the new rule but no customer traffic is actually blocked so that we can measure false positive rates and ensure that the new rules do not cause problems when they are deployed into full production.
Unfortunately, one of these rules contained a regular expression that caused CPU to spike to 100% on our machines worldwide. This 100% CPU spike caused the 502 errors that our customers saw. At its worst traffic dropped by 82%.
This chart shows CPU spiking in one of our PoPs:

We were seeing an unprecedented CPU exhaustion event, which was novel for us as we had not experienced global CPU exhaustion before.
We make software deployments constantly across the network and have automated systems to run test suites and a procedure for deploying progressively to prevent incidents. Unfortunately, these WAF rules were deployed globally in one go and caused today’s outage.
At 1402 UTC we understood what was happening and decided to issue a ‘global kill’ on the WAF Managed Rulesets, which instantly dropped CPU back to normal and restored traffic. That occurred at 1409 UTC.
We then went on to review the offending pull request, roll back the specific rules, test the change to ensure that we were 100% certain that we had the correct fix, and re-enabled the WAF Managed Rulesets at 1452 UTC.
We recognize that an incident like this is very painful for our customers. Our testing processes were insufficient in this case and we are reviewing and making changes to our testing and deployment process to avoid incidents like this in the future.”
Trending Now

Top Tech News Today, March 25, 2026


