Data Cost Optimization Is Now a $9.8B Market, Here Are the Startups Leading the Shift

As cloud-native data platforms become the backbone of modern analytics and AI, managing data costs has become one of the most persistent challenges facing technology leaders. What was once handled through periodic reviews and manual tuning is now a continuous operational concern.
In a recent global survey by Sapio Research, 94% of IT decision-makers reported struggling to manage cloud costs, citing limited visibility into spending and unexpected spikes as their primary pain points. These pressures are accelerating as AI workloads, self-service analytics, and rapid experimentation become standard operating practice in usage-based platforms such as Snowflake, where compute scales elastically, inefficiencies surface immediately as higher spend.
This challenge is no longer niche. The cloud cost management market is valued at approximately $9.8 billion (Global Market Insights). It is projected to grow strongly as enterprises seek better ways to control spend in elastic, consumption-based environments.
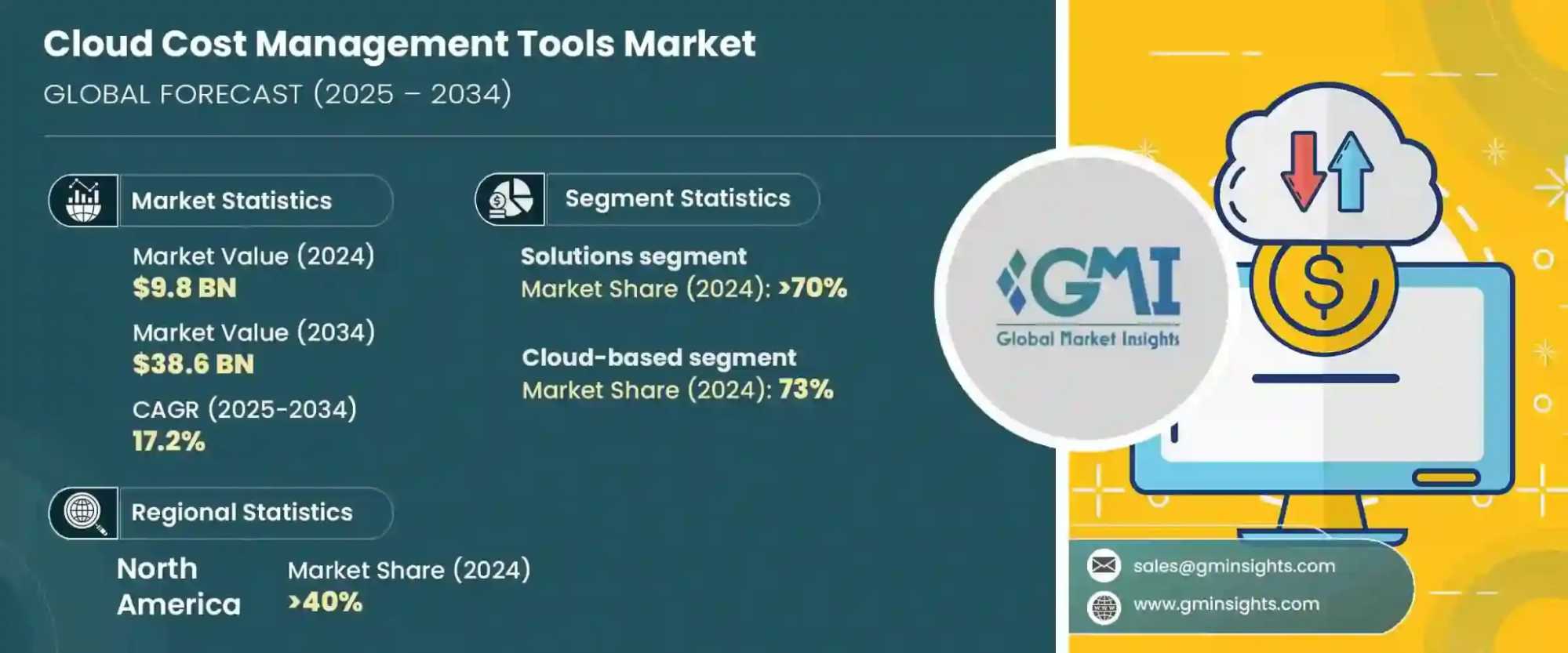
Cloud Cost Management Tools Market
Where Data Cost Optimization Actually Lives
As data platforms have evolved, cost control has shifted from infrastructure planning to usage behavior. In modern cloud data stacks, spend is no longer determined by how much hardware is provisioned, but by 1) how queries are executed, 2) how often data is reused, and 3) how workloads are routed across teams.
This is especially evident in consumption-based platforms such as Snowflake, Databricks, and BigQuery, where compute scales dynamically with demand. In these environments, cost volatility is not an edge case but a default condition. Small inefficiencies, when multiplied across hundreds of users, dashboards, and experiments, quickly compound into material spend, which CFOs scrutinize closely.
How the Data Cost Stack Is Fragmenting
As data usage has scaled, cost control has splintered into distinct functional layers rather than a single solution category. Organizations are discovering that no single tool addresses the entire cost problem, because costs emerge at different points in the data lifecycle.
At the execution layer, cost is created in real time as queries are routed, warehouses scale, and workloads compete for resources. Above that, performance tuning and reliability influence how often data must be reprocessed or rerun. At the organizational level, financial visibility, attribution, and governance shape how teams behave once cost signals are exposed.
This fragmentation explains why the data cost optimization ecosystem now includes a range of startups with complementary focus areas. Some intervene directly in live execution, others improve efficiency over time, and others provide the financial and policy frameworks required to enforce accountability at scale.
Aligning Cost Control with Data Usage
For CIOs and data leaders, the shift is not about choosing a single tool, but about assembling a stack that aligns cost control with how data is actually used. As analytics becomes more democratized and AI workloads remain continuously active, cost management is increasingly treated as a systems problem rather than a reporting exercise.
Snowflake’s interface reflects how query activity and workload growth translate into consumption, highlighting why cost control has become an operational concern.
As a result, the data cost optimization landscape has fragmented into multiple layers. Some solutions focus on real-time execution and optimization, others on performance tuning, reliability, financial visibility, or governance. Together, these layers form an emerging ecosystem designed to restore predictability and control in elastic data environments.
Yukidata (Yuki) | Snowflake Cost Optimization in Real Time
Yukidata’s Snowflake cost optimization platform operates where costs are created: the query path. By working directly within live workloads, Yuki automatically adjusts warehouse size, query routing, and consolidation based on real usage patterns.
Instead of relying on manual tuning cycles or retrospective dashboards, compute is optimized continuously as demand changes. This approach reflects the operational reality of modern data teams, where usage patterns shift constantly and cost volatility emerges in real time.
Built for high-volume Snowflake environments, Yuki combines real-time optimization with enterprise-grade cost controls and forecasting, positioning cost management as an ongoing operational function rather than a periodic clean-up effort.
Monte Carlo | Minimizing Cost Through Data Reliability
Reprocessing driven by data incidents accounts for a significant portion of data spend. Failed pipelines, stale data, and silent errors often lead teams to rerun jobs defensively, increasing compute usage.
Monte Carlo approaches this problem through data observability. By detecting incidents early and restoring trust in data pipelines, organizations can reduce unnecessary reruns and duplicated processing. While not a cost optimization tool by design, improved reliability can have a measurable downstream impact on overall spend.
Keebo | Automated Performance and Efficiency Optimization
Keebo improves data cost efficiency by automating performance optimization for data warehouse workloads. The platform analyzes query behavior and system utilization to identify opportunities to tune and improve efficiency that would otherwise require manual intervention.
Rather than operating directly in the execution path, Keebo focuses on improving how workloads are structured and executed over time. This makes it relevant for teams looking to reduce inefficiencies caused by suboptimal query design or configuration drift, particularly in environments where performance tuning has historically been labor-intensive.
Finout | FinOps and Cloud Cost Visibility Across Data Platforms
Finout approaches the data cost challenge from a financial operations perspective. The platform provides centralized visibility into cloud and data platform spending, enabling organizations to track, allocate, and forecast costs across teams and environments.
By bridging engineering usage with financial accountability, Finout helps organizations understand how data platform consumption maps to budgets and business units. While it does not directly optimize execution, it plays a critical role in governance and decision-making by making cost signals accessible to finance and leadership teams.
Select | Cost Attribution and Spend Insight
Understanding where data costs originate is a prerequisite for effective control. Select provides granular visibility into query-level spend, highlighting which users, workloads, and models consume the most compute.
This level of attribution enables finance and platform teams to identify inefficiencies and prioritize optimization efforts. Visibility alone does not change behavior, but it establishes the foundation required for disciplined cost management.
Immuta | Policy-Driven Usage Governance
Immuta approaches data cost control through access governance. By enforcing fine-grained policies around who can query which datasets, organizations can limit unnecessary usage of high-cost data assets, particularly in regulated environments.
While governance does not optimize execution directly, it shapes usage behavior in ways that reduce avoidable consumption and reinforce accountability.
Alation | Reducing Duplication Through Better Discovery
Poor data discoverability is a standard driver of duplicated work. When teams cannot easily find or trust existing datasets, they often rebuild logic or rerun transformations, increasing compute usage.
Alation is a data catalog platform that helps organizations document, discover, and reuse data assets. Its impact on cost is indirect and dependent on adoption, but improved discovery can reduce redundant workloads over time.
Why This Shift Is Happening Now
Data cost inefficiencies rarely stem from a single slow query. They emerge when usage scales faster than visibility, governance, and operational controls can adapt.
This dynamic has intensified as AI workloads, self-service analytics, and always-on experimentation push data platforms into continuous use. In elastic environments where consumption is tightly coupled to spend, traditional approaches such as after-the-fact dashboards and periodic tuning no longer scale. As a result, organizations are shifting toward systems that influence costs when data is used, rather than after costs have already been incurred.
Takeaway for CIOs, CTOs and Data Leaders
Data cost optimization has evolved into a strategic operational discipline. As elasticity becomes the default, organizations can no longer rely on periodic audits or manual tuning alone. Effective control now requires systems that operate continuously, surface early signals, and align data usage with business value.
The five companies highlighted above reflect this evolution, from real-time optimization to reliability, visibility, and governance. Together, they illustrate how data cost control is being redefined.
Trending Now

Top Tech News Today, April 2, 2026


